
希尔排序
文章参考:知乎-冒泡 、wiki 、chatGPT、知乎-helloCode
希尔排序是一种不稳定排序算法,最坏复杂度为 O(N2) ,但它是插入排序的改进版本,是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位,即每次只能消除一个逆序对
假设我们要从小到大排序,一个数组中取两个元素如果前面比后面大,则为一个逆序,容易看出排序的本质就是消除逆序数,可以证明对于随机数组,逆序数是O(N2) 的,而如果采用交换相邻元素的办法来消除逆序,每次正好只消除一个,因此必须执行O(N2)的交换次数,这就是为啥冒泡、选择、插入等算法只能到平方级别的原因,反过来,基于交换元素的排序要想突破这个下界,必须执行一些比较,交换相隔比较远的元素,使得一次交换能消除一个以上的逆序,希尔、快排、堆排等等算法都是交换比较远的元素,只不过规则各不同罢了。
——引自知乎-冒泡这段总结真是醍醐灌顶!!!不过有个问题,插入排序并非交换相邻元素,为什么其复杂度仍为 O(N2) 呢?
那么希尔排序是如何进行的呢?概括其思路: 先将数组分为多个(不连续,大跨度)小数组,对每个小数组排序,从而使大数组相对有序,最终对整个数组进行插入排序,而此时数组已经大概有序了,插入排序就能高效地进行 。为什么要大跨度? 因为这样可以让一个元素一次性地朝最终位置前进一大步,从而在一次交换中尽可能多地消除逆序对 。比如在下面图解的第一轮交换中,6就成功地向正确位置移动了一大步!而对于插入排序而言,6必须要经过很多次交换才能到达最终位置。
看以下图解:
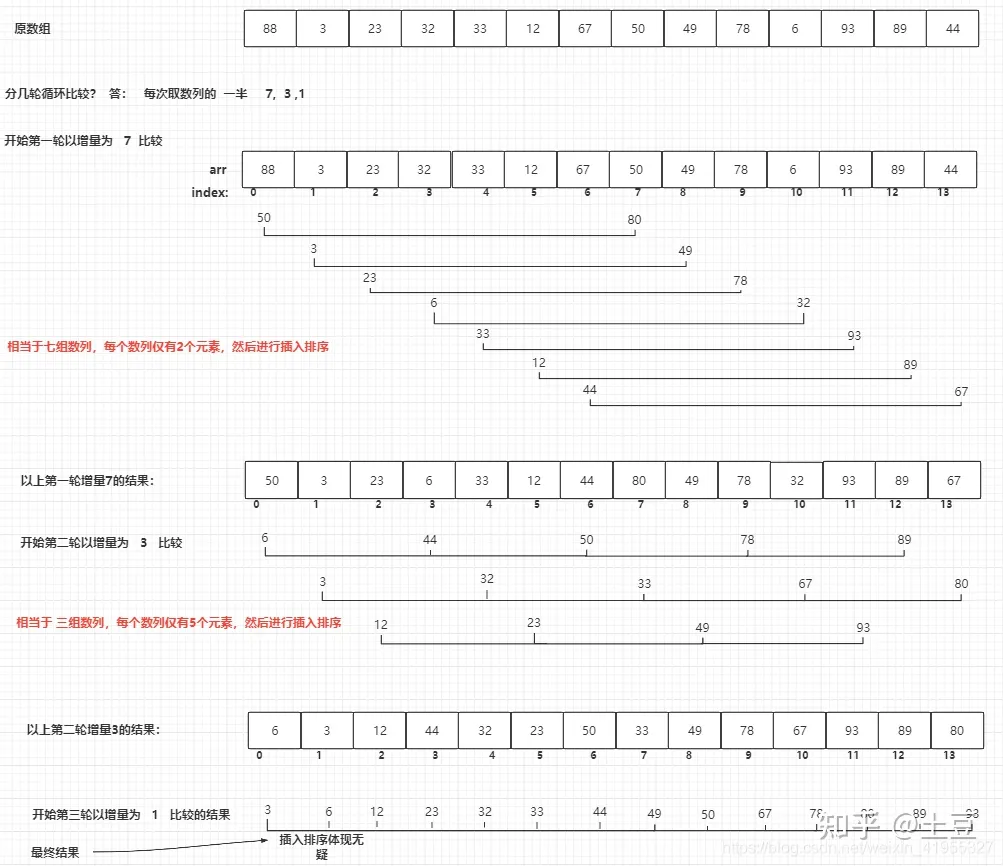
第一次步长为 7,那么一次交换就可能消除最多 7 个逆序对!这或许就是比插入排序更高级的原因吧。下面直接给出 C++ 描述:
template<class T, class cmptor>
void shellSort(T* vec, int len, cmptor cmp)
{
for(int gap = len/2; gap > 0; gap /= 2) //gap>0而不可gap>=0!!!
{
for(int g = 0; g < gap; g++)
{
//insert sort
for(int i = g+gap; i < len; i += gap)
{
for(int k = i; k > g; k -= gap) //注意是k>g而不是k>0
{
if(cmp(vec[k-gap], vec[k]))
swap(vec[k-gap], vec[k]);
else
break;
}
}
}
}
}
- 步长=组数!见上示意图
- i 相当于每组的起始下标
- 8 行后参见插入排序
另外,这里我们的步长 gap 每次递减 1/2 ,实际上这并不高效。步长的选择是希尔排序的重要部分,将直接影响最终的排序效率! 常用步长序列有以下几种:常用的步长序列有以下几种:
- 希尔原始序列:希尔最初提出的间隔序列是使用 n/2 作为初始间隔,然后每次缩小一半,直到间隔为 1 。
- Hibbard 序列:Hibbard 序列使用 2^k - 1 作为间隔,其中 k 从初始间隔递减到 1 。例如,对于数组长度为 n 的序列,Hibbard 序列为1, 3, 7, 15, …, 2^k - 1。
- Sedgewick 序列:Sedgewick 序列是由 Robert Sedgewick 提出的一种间隔序列。它结合了希尔原始序列和 Hibbard 序列的优点,并且在实践中表现良好。Sedgewick 序列的具体定义较为复杂,可以参考相关文献进行了解。
优点
- 相对于传统的插入排序,希尔排序通过将元素分组进行排序,减少了逆序对的数量,从而加快了排序过程。
- 希尔排序是原地排序算法,只需在原始数组上进行元素的交换和移动,不需要额外的辅助空间。
缺点
- 希尔排序的最坏情况时间复杂度并不稳定,通常在 O(N2) 到 O(NlogN) 之间。虽然平均情况下性能较好,但在某些特定情况下,性能可能不如其他高级排序算法。
- 步长序列的选择对性能产生影响,选择不当可能导致排序效率下降。